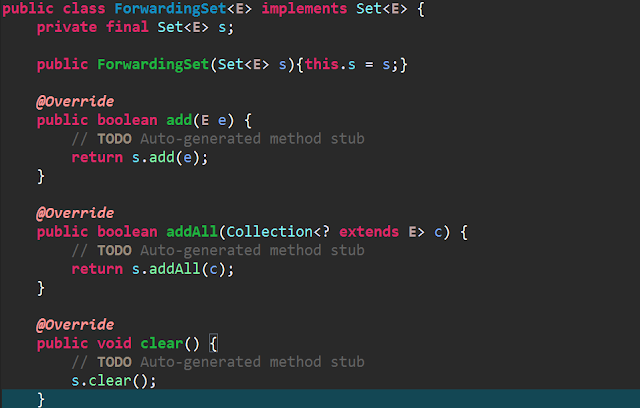
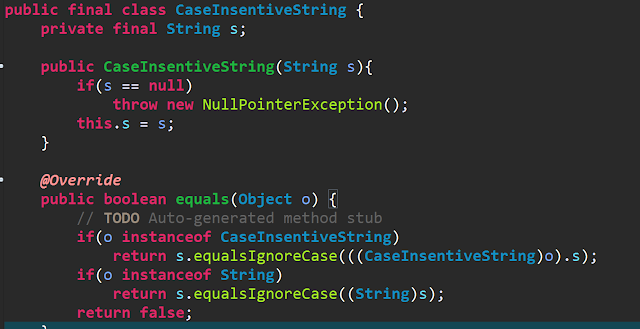
* 장인정신을 익히는 법 1. 장인에게 필요한 원칙, 패턴, 기법, 경험이라는 지식을 습득 2. 열심히 일하고 연습해 지식을 몸과 마음으로 체득 나쁜코드를 양산하면 오히려 기한을 맞추지 못한다. 나쁜 코드로 속력이 즉각 늦어져서 기한을 놓친다. 기한을 맞추는 방법, 그러니깐 빨리가는 유일한 방법은, 언제나 코드를 깨끗히 유지하는 것이다. <클린코드란?> by C++ 창시자 창문이 깨진 건물은 누구도 상관하지 않는다는 인상을 품긴다. 그래서 사람들도 관심을 끊는다. 창문이 더 깨져도 상관하지 않는다. 마침내 자발적으로 창문을 깬다. 외벽에 그려진 낙서를 방치하고 차고에 쓰레기가 쌓여도 치우지 않는다. 일단 창문이 깨지고 나면 쇠퇴하는 과정이 시작된다. 세세한 사항까지 꼼꼼하게 신경을 쓰라는 소리다. 프로그래머들이 대충 넘어가는 부분중 하나가 오류처리다. 메모리 누수, 경쟁상태, 일관성 없는 명명법이 또 다른 예다. 잘쓴 코드란 자신이 좋아했던 책을 읽었던 기억을 떠올려봐라. 마치 책을 읽는동안 단어가 사라지고 이미지가 떠오르는 듯한 코드!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! <간단한 코드 규칙> 모든 테스트를 통과한다. 중복이 없다. 시스템 내 모든 설계 아이디어를 표현한다. 클래스, 메소드, 함수 등을 최대한 줄인다. * 프로그램은 아주 유사한 요소로 이루어 졌다. 한 가지 예가 '집합에서 항목 찾기'이다. 직원 정보가 저장된 데이터베이스든 키/값 쌍이 저장된 해시 맵이든, 여러 값을 모아놓은 배열이든 이런상황이 발생하면 추상메소드나 추상클래스를 만들어서 실제 구현을 감싼다. 그러면 장점이 생긴다. 실제 기능은 아주 간단한 방식으로, 예를들어 해시맵으로, 구현해도 괜찮다. 다른 코드는 추상 클래스나 추상 메소드가 제공하는 기능을 사용하므로 실제...