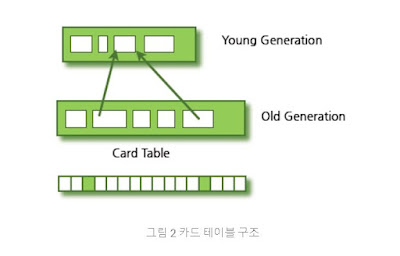
n-2 개의 숫자가 Array나 List에 저장되어 있습니다. 원래는 n개의 일련숫자(이를테면 6,7,8,9,..,6+(n-1)) 였는데, 가장 작은 수와 가장 큰 수를 제외하고 숫자 두개를 삭제한 후에 순서를 랜덤하게로 재 배열한 것입니다. (즉, Sorting이 되어있지 않습니다.) 문제는 제거된 두 숫자를 찾아내는 것인데, 조건은 계산에 필요한 storage에 제약이 있습니다. 즉, O(N)보다 작다는 것입니다. (참고로 O(n)개의 storage 가 주어진다면 너무나 쉬운 문제가 되겠지요?) 그리고 Computing Time은 O(n)입니다. 예를 들어서 12,7,9,5,4,10,11 이 주어진다면, 없어진 두 숫자는 6과 8이 되겠네요. (하루나 이틀후에 답이 없으면, 답을 올리겠습니다. 정답이 반드시 하나일 필요는 없겠지요.) 답: 전체 엘리먼트와 합과, 전체 엘리먼트의 곱을 계산하면 되네요. 2개의 숫자를 빼기 전의 숫자들은 중간에 빠지는 숫자가 없는 일련 번호니까, 전체 합과 곱이 어떤 값이어야 하는 지 알 수 있습니다. 이제, 두개의 숫자를 X, Y라고 하면, X + Y = A, X*Y = B 에서 A, B의 위의 계산에서 알 수 있습니다. public static void main(String[] args) { // TODO Auto-generated method stub int[] number={4,5,7,9,10,11,12}; int lastIndex=number.length-1; int size=number[lastIndex]-number[0]+1; int sumTotal=(number[0]+number[lastIndex])*size/2; int mulTotal=1; for(int i=number[0];i<=number[number.length-1];i++){ mulTotal*=i; } int p...