(Java 소스 분석) Fork Join Framework
*Arrays클래스의 sort메소드를 보던 중,
parallelSort()라는 메소드를 보게 되었다.
이 정렬 메소드는 DualPivotQucikSort를 사용하여 일반 sort()메소드와 같지만, 다중 스레드를 사용할시 훨씬 좋은 정렬 성능을 보인다고 나와있다.
특히, 메소드 안에 다음과 같은 조건이있다.
p = ForkJoinPool.getCommonPoolParallelism()) == 1
ForkJoinPool은 기본 개념은 큰 업무를 작은 업무 단위로 쪼개고, 그것을 각기 다른 CPU에서 병렬로 실행한후 결과를 취합하는 방식이다. 마치 분할정복 알고리즘과 흡사하다. 여러 CPU들을 최대한 활용하면서 동기화와 GC를 피할수 있는 여러 기법이 사용되었기 때문에, Java 뿐 아니라 Scala에서도 널리 쓰이고 있는 병렬처리 기법이다. 또한 C,C++을 위한 Thread Building Block(TBB) 나 C#의 Task Parallel Library또한 Fork Join Framework의 개념을 가지고 있다.
*ForkJoinPool의 절차를 조금 더 보자면
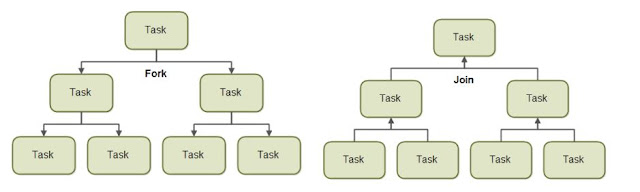
1) 큰 업무를 작은 단위의 업무로 쪼갠다.
2) 부모 쓰레드로부터 처리로직을 복사하여 새로운 쓰레드에서 쪼개진 업무를 수행(Fork)시킨다.
3) 2을 반복하다가, 특정 쓰레드에서 더 이상 Fork가 일어나지 않고 업무가 완료되면 그 결과를 부모 쓰레드에서 Join하여 값을 취합한다.
4) 3을 반복하다가 최초에 ForkJoinPool을 생성한 쓰레드로 값을 리턴하여 작업을 완료한다.
<ForkJoinPool의 성능의 핵심 : Work-Stealing>
기본적으로는 newCachedThreadPool이나 newFixedThreadPool 처럼 ExecutorService의 구현체이다.
그러나 일반 ExecutorService 구현 클래스와는 기본적으로 다른 점이 하나 존재한다.
바로 work-stealing 알고리즘이 구현되어 있다는 점이다.
일반적으로 멀티쓰레드 프로그래밍을 할때 어려운 점중의 하나는 CPU자원을 골고루 사용하여 최대한의 성능을 뽑아내는 일이다. 정확히 어느정도의 CPU자원이 소모되는 일인지 가늠하기 힘든 경우 Task를 어떻게 나누는지에 따라서 노는(Idle) CPU시간이 많아 질수도 있다.
ForkJoinPool의 work-stealing은 이런 경우를 효과적으로 해결한다.

parallelSort()라는 메소드를 보게 되었다.
이 정렬 메소드는 DualPivotQucikSort를 사용하여 일반 sort()메소드와 같지만, 다중 스레드를 사용할시 훨씬 좋은 정렬 성능을 보인다고 나와있다.
특히, 메소드 안에 다음과 같은 조건이있다.
p = ForkJoinPool.getCommonPoolParallelism()) == 1
ForkJoinPool은 기본 개념은 큰 업무를 작은 업무 단위로 쪼개고, 그것을 각기 다른 CPU에서 병렬로 실행한후 결과를 취합하는 방식이다. 마치 분할정복 알고리즘과 흡사하다. 여러 CPU들을 최대한 활용하면서 동기화와 GC를 피할수 있는 여러 기법이 사용되었기 때문에, Java 뿐 아니라 Scala에서도 널리 쓰이고 있는 병렬처리 기법이다. 또한 C,C++을 위한 Thread Building Block(TBB) 나 C#의 Task Parallel Library또한 Fork Join Framework의 개념을 가지고 있다.
*ForkJoinPool의 절차를 조금 더 보자면
1) 큰 업무를 작은 단위의 업무로 쪼갠다.
2) 부모 쓰레드로부터 처리로직을 복사하여 새로운 쓰레드에서 쪼개진 업무를 수행(Fork)시킨다.
3) 2을 반복하다가, 특정 쓰레드에서 더 이상 Fork가 일어나지 않고 업무가 완료되면 그 결과를 부모 쓰레드에서 Join하여 값을 취합한다.
4) 3을 반복하다가 최초에 ForkJoinPool을 생성한 쓰레드로 값을 리턴하여 작업을 완료한다.

<ForkJoinPool의 성능의 핵심 : Work-Stealing>
기본적으로는 newCachedThreadPool이나 newFixedThreadPool 처럼 ExecutorService의 구현체이다.
그러나 일반 ExecutorService 구현 클래스와는 기본적으로 다른 점이 하나 존재한다.
바로 work-stealing 알고리즘이 구현되어 있다는 점이다.
일반적으로 멀티쓰레드 프로그래밍을 할때 어려운 점중의 하나는 CPU자원을 골고루 사용하여 최대한의 성능을 뽑아내는 일이다. 정확히 어느정도의 CPU자원이 소모되는 일인지 가늠하기 힘든 경우 Task를 어떻게 나누는지에 따라서 노는(Idle) CPU시간이 많아 질수도 있다.
ForkJoinPool의 work-stealing은 이런 경우를 효과적으로 해결한다.
그림 1)에서 보면 타스크가 클때는 Fork를 통해서 업무를 분할 한다고 했다. 이렇게 분할 된 업무는 그림 B)의 submit과정을 통해 inbound queue에 차곡 차곡 쌓이게 된다. queue에 들어온 task들은 ForkJoinPool에 할당된 CPU만큼의 쓰레드 개수(여기서는 A와 B두개)로 Task가 분산된다. 이때 각 쓰레드들은 내부적으로 각자의 Queue(정확히는 Push/Pop도 가능한 Dequeue)를 가지고 있어 업무를 큐에 추가 한후에, 차례차례 수행하게 된다. 그런데 만약 그림2)의 B쓰레드처럼 모든 일을 다 처리해서 더이상 할일이 없는 경우, CPU자원이 놀게 된다(Idle). 이런 상황에서 work-stealling이 동작하게 되면 A쓰레드 큐에 남은 Task를 B에서 가져와서 처리를 하는 식으로 구현을 해주면 CPU가 놀지않고 최적의 성능을 낼수 있다.
그림 2)
위처럼 놀고 있는 쓰레드B에게 넘겨줄만한 작업을 찾았으면 A는 B에거 어떤 작업을 훔쳐가면 되는지 알려준다. 만약 적당한 일거리를 찾지 못하면 Fail메시지를 날린다. 쓰레드 B는 상황에 따라 쓰레드 A에서 업무를 훔쳐올지 shared inbound queue에서 업무를 가져올지 결정한다.
알고리즘이 효율적으로 구현되어있다면 매우 효율적으로 CPU가 병렬로 서로 도와가며 최대한 빠른 시간안에 업무를 처리하게 된다.

댓글
댓글 쓰기