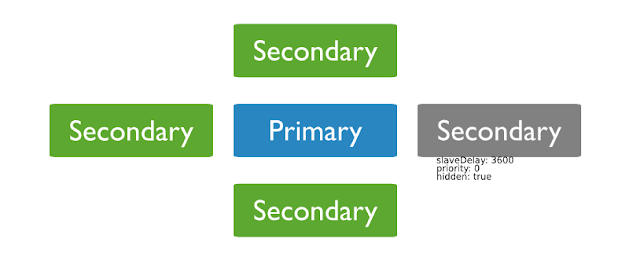
(MongoDB) Replica Set Arbiter

* Arbiter 는 데이터셋을 복사할 수 없고 primary가 될 수 없다. 레플리카 셋들은 arbiters를 가질 수 있고 primary를 선정하기 위해 투표를 한다. Arbiters 항상 1개의 표를 행사한다. 결국 Primary가 죽어 새로운 Primary를 선정하기 위해서는 투표가 이뤄지게되고, Arbiter가 한표를 행사하게 되면서 홀수 표가 되어 새로운 레플리카셋을 생성하는 오버헤드가 없어지게 된다. 중요사항 : Do not run an arbiter on systems that also host the primary or the secondary members of the replica set aribter를 가지고 있는 레플리카 셋에서, 프로토콜 버전1 (pv1) 은 프로토콜 버전 0 (pv 0)과 비교했을 때 rollback의 가능성을 증가시킨다. w:1 예) 예를들어 다음과 같은 replica set에서 arbiter가 있으므로 투표결과가 홀수가 되게 만든다. <Security> Authentication : aribiter는 데이터를 저장하지 않는다. 그래서 aribiter는 유저테이블 그리고 권한인증을 위한 맵핑정보가 없다. 그래서 local host Exception을 이용해 로그를 남긴다. Communication : arbiters와 다른 set 멤버들간의 유일한 커뮤니케이션은 투표, heartbeats 그리고 configuration data이다. 이것들은 암호화되지 않는다. 그러나 만약 몽고db 배치가 TLS/SSL이면 커뮤니케이션은 암호화된다. * Local host Exception ?