(머신러닝) 4장. 나이브베이스: 확률 이론으로 분류하기
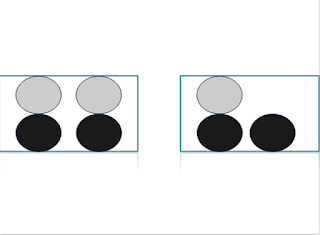
*나이브 베이스 장점: 소량의 데이터를 가지고 작업이 이루어지며, 여러 개의 분류 항목을 다룰 수 있다. 단점: 입력 데이터를 어떻게 준비하느냐에 따라 민감하게 작용한다. 적용: 명목형 값 1. 조건부확률 7개의 돌이 담긴 병이있다. 병 속의 돌중 3개는 회색 4개는 검은색이다. 이 병에 손을 넣고 임의로 돌 하나를 뽑는다면, 뽑은 돌이 회색일 가능성은 3/7이다. 만약에 7개의 돌이 두 개의 양동이(bucket)에 있다면 어떻게 될까? 만약 P(회색) 나 P(검은색)을 계산하고자 한다면 양동이에 따라 답이 변하지 않겠는가? 만약 양동이 B에 회색 돌의 확률을 계산하고자 한다면, 아마도 회색 돌의 확률을 계산하는 방법을 알 수 있을 것이다. 이것을 조건부확률 이라고한다. P(회색|bucketB)='양동이 B에 주어진 회색 돌의 확률' 이것은 1/3으로써, P(회색|Bucket B)=P(회색 and Bucket B)/P(Bucket B)이다.==>(1/7)/(3/7) 조건부 확률을 다루기 위한 다른 유용한 방법으로 베이스 규칙이 있다. 만약에 P(x|c)를 알고 있는 상태에서 P(c|x)를 알기를 원한다면 다음과 같이 찾을 수 있다. P(c|x)=(P(x|c)*P(c))/(P(x)) <나이브 베이스에 대한 일반적인 접근 방법> 1. 수집 2. 준비: 명목형 또는 부울형(Boolean)값이 요구된다. 3. 분석: 많은 속성들을 플롯 하는 것은 도움되지 못한다. 히스토그램으로 보는 것이 가장좋다. 4. 훈련: 각 속성을 독립적으로 조건부 확률을 계산한다. 5. 검사: 오류율을 계산한다. *속성들이 서로 독립적이라고 가정하면, N^1000개의 데이터는 1000*N개로 줄어들게 된다. 독립이라는 것은 통계적인 독립을 의미한다. 즉, 하나의 속성 또는 단어가 다른 단어 옆에도 있는 가능성이 있다는 것이다. '베이컨'이 '맛있는' 이라는 단...
