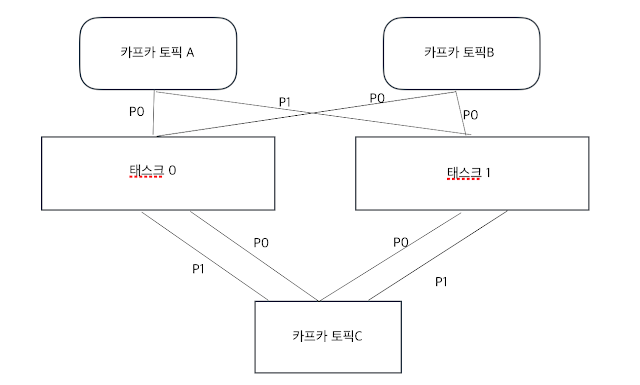
(kafka) 장애 복구 정리

1. WAS -> Kafka (연결불가능) 이 경우 Producer(소셜엔진) 에서 카프카로 데이터 전송시 exception이 발생 이 exception을 소셜엔진엔서 callback을 이용해 실패로그로 저장하던지 MongoDB에 저장하여 실패 데이터를 기록 이와 같은 케이스는 다음과 같은 방법으로 실패를 처리할 수 있다 1) retries 옵션에 적당한 값을 설정해 실패 시 재시도 (엄청난 지연 발생가능) 2) 전송 실패시 발생하는 Exception을 catch에 큐에저장 후 다시 재전송 실패가 지속되면 카프카 문제로 판단해 실패로그를 저장 혹은 MongoDB 에 해당 데이터 저장 참고 : http://readme.skplanet.com/?p=13042 Scenario 1 - Fire-and-forget with a failed node and partition leader fail-over (acks=0) 이 케이스는 프로듀서에서 acknowledgements를 받지 않는다. 즉, 전송만 계속하는 것으로 만약 현재 카프카 호스트의 Leader 가 다운된다면 가정) 약 10만개 메시지 전송 중, 3만개 메시지 전송 중, 카프카 leader가 down되었을 때 새로운 leader를 선출하게된다. 이 텀동안 데이터 유실이 발생 약 6700여개 메시지 전송 실패 Scenario 2 - Acks=1 with a failed node and partition leader fail-over ack0=1인 경우, Leader노드가 fail된 경우. 이 케이스 또한 데이터 유실이 발생한다. 그러나 acks=0 인 경우보다 데이터 유실 발생이 더 적다. 테스트) 10만 메시지를 한개의 Producer에서 전송했을 때, 3만번쨰에서 Leader가 죽고, 새로운 Leader 가 선출되었을때, 약 5개의 데이터 손실 발생, 약 9만개 메시지는 Producer 에 응답함 ...