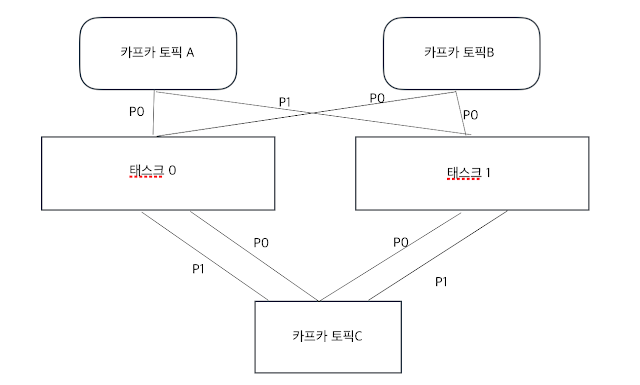
카프카는 고성능, 고가용성 메시징 애플리케이션으로 발전하는데 토픽과 파티션이라는 데이터 모델을 이용한다. 토픽은 메시지를 받을 수 있도록 논리적으로 묶은 개념이고, 파티션은 토픽을 구성하는 데이터 저장소로서 수평 확장이 가능한 단위이다. 1. 토픽의 이해 카프카 클러스터는 토픽이라 불리는 곳에 데이터를 저장한다. 토픽은 메일주소 시스템이라고 생각하면 쉽다. 토픽이름은 249자 미만으로 영문, 숫자, ' . ' , ' _ ', ' - ' 를 조합하여 자유롭게 만들 수 있다. 1개의 메시지를 보내는데 1초가 걸린다면, 4개의 메시지를 각각 보내게 되면 4초가 걸리게 된다. 큐시스템에서 한 가지 제약조건은, 메시지의 순서가 보장되어야 한다. 그렇게 때문에 이전메시지 처리가 완료된 후 다음 메시지를 처리하게 된다. 그래서 토픽안에 4개의 파티션을 만들어서 보낸다면 1초가 걸리게 된다. 무조건 파티션수를 늘려야 할까? 다음과 같은 단점이 있다. 파일 핸들러의 낭비 -> 각 파티션은 브로커의 디렉토리와 매핑 되고, 저장되는 데이터마다 2개의 파일(인덱스와 실제 데이터)이 있습니다. 카프카에서는 모든 디렉토리의 파일들에 대해 파일 핸들을 열게 됩니다. 결국 파티션의 수가 많을 수록 파일 핸들 수 역시 많아지게 되어 리소스를 낭비하게 됩니다. 장애 복구 시간 증가 - > 카프카는 높은 가용성을 위해 리플리케이션을 지원한다. 브로커에는 토픽이 있고, 토픽은 여러 개의 파티션으로 나뉘어지므로 브로커에는 여러 개의 파티션이 존재한다. 또한 각 파티션마다 리플리케이션이 동작하게 되며, 하나는 파티션의 리더이고 나머지는 파티션의 팔로워가 된다. 만약 브로커가 다운되면 해당 브로커에 리더가 있는 파티션은 일시적으로 사용할 수 없게 되므로, 카프카는 리더를 팔로워 중 하나로 이동시켜 클라이언트 요청을 처리할 수 있게된다. 이와같은 장애 처리는 컨트롤러...