(정보처리기사) 전자계산기 구조
<주요 레지스터의 종류 및 기능>
- 프로그램카운터, 프로그램 계수기(PC:Program Counter): 다음 번에 실행할 명령어의 번지를 기억하는 레지스터
- 명령레지스터(IR: Instruction Register): 현재 실행중인 명령의 내용을 기억하는 레지스터
- 누산기(AC: Accumuluator): 연산된 결과를 일시적으로 저장하는 레지스터로 연산의 중심이다.
- 상태레지스터(Status Register), PSWR(Program Status Word Register), 플래그 레지스터: 시스템 내부의 순간순간의 상택 기록된 정보를 PSW라고 하며, 오버플로,언더프로, 자리올림, 인터럽트등의 PSW를 저장하고 있는 레지스터
- 메모리 주소 레지스터(MAR:Memory Address Register):기억장치를 출입하는 데이터의 번지를 기억하는 레지스터
- 메모리 버퍼 레지스터(MBR:Memory Buffer Register): 기억장치를 출입하는 데이터가 잠시 기억되는 레지스터
- 인덱스 레지스터: 주소의 변경이나 프로그램에서의 반복연산의 횟수를 세는 레지스터
- 데이터 레지스터: 연산에 사용될 데이터를 기억하는 레지스터
- Shift register: 저장된 값을 왼쪽 또는 오른쪽으로 1Bit씩 자리를 이동시키는 레지스터, 2배길이 레지스터라고도 한다.
- 메이저 스테이터스 레지스터(Major status register): CPU의 메이저상태를 저장하고 있는 레지스터
- Fetch Cycle은 명령어를 주기억 장치에서 중앙처리 장치의 명령 레지스터로 가져와 해독하는 단계이다.
- 해석된 명령어의 모드 비트에 따라 직접 주소와 간접주소를 판단한다.
- 모드 비트가 0이면 직접주소이므로 Execute단계로 변천한다.
- 모드 비트가 1이면 간접주소이므로 Indirect단계로 변천한다.

*****FLOPS는 컴퓨터의 연산속도를 나타내는 단위로 FLoating-point OPerations Per Second의 약자이다. 즉 1초당 부동소수점 연산 명령을 몇 번 실행 할 수 있는 지를 말한다.
MFLOPS에서 M은 Mega를 말하는 것으로 1초에 부동소수점 연산을 백만번 수행함을 의미한다.
Mege=2의 20승
GFLOPS는 1초에 부동소수점 연산을 10억번 수행
Giga=2의 30승
<우선순위 인터럽트 운영방식>
1. 인터럽트 요청 신호 발생
2. 프로그램 실행을 중단: 현재 실행중이던 명령어는 끝까지 실행
3. 현재 프로그램 상태를 보존: 프로그램 상태는 다음에 실행할 명령의 번지를 말하는 것으로서 PC(프로그램 카운터)가 가지고 있음. PC의 값을 메모리의 0번지에 보관
4. 인터럽트 처리 루틴을 실행: 인터럽트 처리 루틴을 실행하여 인터럽트를 요청한 장치를 식별
5. 인터럽트 서비스(취급)루틴을 실행: 실질적인 인터럽트를 처리
6. 상태 복구: 인터럽트 요청 신호가 발생했을 때 보관한 PC의 값을 다시 PC에 저장
7. 중단된 프로그램 실행 재개:PC의 값을 이용하여 인터럽트 발생 이전에 수행중이던 프로그램을 계속 실행
<명령어의 구성>
컴퓨터에서 실행되는 명령어는 크게 연산자에 해당하는 연산자(Operation Code)부와 명령에 필요한 자료의 정보가 표시되는 자료(Operand)부로 구성된다.

<매핑 프로세스의 종류>
<우선순위 인터럽트 운영방식>
ㆍLCFS(Last Come First Service) : 가장 나중에 인터럽트를 요청한 장치에게 가장 높은 우선순위를 부여한다.
ㆍFCFS(First Come First Service) : 가장 먼저 인터럽트를 요청한 장치에게 가장 높은 우선순위를 부여한다.
ㆍMasking Scheme : 어떤 인터럽트가 처리 중일 때 그보다 높은 우선순위의 인터럽트만 허용한다.
<채널의 종류>
- 선택채널(Select Channel): 고속 입.출력 장치(자기디스크,자기 테이프, 자기 드럼)와 입.출력하기 위해 사용함, 특정한 한개의 장치를 독점하여 입.출력함
- 다중채널(Multiplexer Channlel): 저속 입.출력 장치(카드리더,프린터)를 제어하는 채널, 동시에 여러개의 입.출력장치를 제어함
- Block Multiplexer Channel: 고속 입.출력 장치를 제어하는 채널, 동시에 여러개의 입출력 장치를 제어함
<인터럽트 동작원리>
1. 인터럽트 요청 신호 발생
2. 프로그램 실행을 중단: 현재 실행중이던 명령어는 끝까지 실행
3. 현재 프로그램 상태를 보존: 프로그램 상태는 다음에 실행할 명령의 번지를 말하는 것으로서 PC(프로그램 카운터)가 가지고 있음. PC의 값을 메모리의 0번지에 보관
4. 인터럽트 처리 루틴을 실행: 인터럽트 처리 루틴을 실행하여 인터럽트를 요청한 장치를 식별
5. 인터럽트 서비스(취급)루틴을 실행: 실질적인 인터럽트를 처리
6. 상태 복구: 인터럽트 요청 신호가 발생했을 때 보관한 PC의 값을 다시 PC에 저장
7. 중단된 프로그램 실행 재개:PC의 값을 이용하여 인터럽트 발생 이전에 수행중이던 프로그램을 계속 실행
<명령어의 구성>
컴퓨터에서 실행되는 명령어는 크게 연산자에 해당하는 연산자(Operation Code)부와 명령에 필요한 자료의 정보가 표시되는 자료(Operand)부로 구성된다.

*연산자부(OP_Code)
- 연산자부는 수행해야 할 동작에 맞는 연산자를 표시한다.
- 연산자부의 크기(비트수)는 표현할 수 있는 명령의 종류를 나타내는 것으로 n비트면 2의n승 개의 명령어를 사용 할 수 있다.
- 연산자부에는 주소부의 유효 주소가 결정되는 방법을 지정하기 위한 모드비트를 추가하긷 한다.(0: 직접, 1:간접)
*Operand부(주소부)
- 주소부는 실제 데이터에 대한 정보를 표시하는 부분이다.
- 기억장소의 주소,레지스터 번호, 사용할 데이터 등을 표시한다.
- 주소부의 크기는 메모리의 용량과 관계가 있다.
예) 주소부가 16비트라면 2^16=65,536=64k의 메모리를 주소로 지정하여 사용 할 수 있다.
<Memory Interleaving>
한편 4개의 뱅크로 구성된 메모리로 위와 같은 작업을 한다고 하면 다음과 같이 된다.
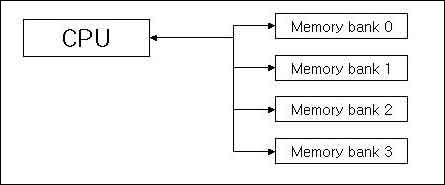 |
1. CPU가 Bank#0에 어드레스 #0을 보낸다.
2. CPU가 어드레스 #1을 Bank#1에 보내고 Data#0을 Bank#0에서 받는다.
3. CPU가 어드레스 #2를 Bank#2에 보내고 Data#1을 Bank#1에서 받는다.
4. CPU가 어드레스 #3을 Bank#3에 보내고 Data#2을 Bank#2에서 받는다.
5. CPU가 Data#3를 Bank#3에서 받는다.
 |
즉 한 개의 뱅크가 리프레쉬를 하고 있을 경우 다른 뱅크는 액세스를 하여 순차적인 접근 방법보다 병렬화된, 파이프라인 접근 방법으로 클럭사이클을 줄이면서 데이터를 읽어와 전체적으로 대역폭이 늘어난 효과를 메모리 자체를 고속화 시키거나 입/출력 포트를 늘리지 않고 이루어 낼 수 있는 것이다. 물론 위의 예는 실제 메모리 인터리빙과 완전히 동일하지 않음을 밝힌다. 실제 DRAM의 RAS Access Time, Precharge time, 그리고 Cycle time이 위에서 대략적으로 제시한 것과 같지는 않기 때문이다.
단순한 예를 들어 계산으로 Access Time이 클럭 사이클의 절반, Precharge Time도 클럭 사이클의 절반으로 계산할 경우 , 4 way 뱅크 인터리빙으로 이론상으로는 기존 메모리를 고속화 시키지 않고도 대역폭은 4배가 늘어나는 효과를 볼 수 있게 된다.
그러나 이 뱅크 인터리빙의 경우 CPU가 요구하는 데이터 어드레스가 같은 뱅크에 위치할 경우에는 당연히 다시 리프레쉬를 거친후에 뱅크에서 데이터를 읽어와야 하기 때문에 항상 높은 대역폭을 얻을 수 있는 것은 아니다.
현재 출시중인 대부분의 SDRAM DIMM 모듈을 2 Bank나 4 Bank로 구성되어 있다. 2 Bank 모듈의 경우 대부분 16Mbit의 SDRAM 칩으로 구성되어 32MB의 작은 용량인데, 실제 현재 다수로 사용되는 64/128MB의 SDRAM DIMM의 경우 64Mbit - 256Mbit의 칩으로 구성되어 있으며 4 bank로 구성되어 있다.
하지만 뱅크 인터리빙이 만병 통치약은 아니고, 이를 구현하는데에도 당연히 단점이 따른다. 일단 뱅크수만을 늘린다고 해서 장땡은 아니라는 것이다. 뱅크수를 늘린다고 하면 Memory Depth가 늘어가 나게 되며 이는 전적으로 저렴한 메모리로 고성능 구현이라는 목표에 역행할 수도 있기 때문이다.
여하튼 메모리 인터리빙으로 실제 애플리케이션에서는 어느정도 성능 향상을 불러올 수 있는지 ABIT의 KT7A으로 테스트를 진행하여 보았다 결과를 보도록 하자.
<매핑 프로세스의 종류>
- 직접 매핑(Direct Mapping)
- 어소시에이티브 매핑(Associative Mapping)
- 세트-어소시에이티브 매핑(Set-Associative Mapping)
<사이클 스틸(Cycle Steal)>
- 데이터 채널(DMA 제어기)과 CPU가 주기억장치를 동시에 Access할 때 우선순위를 데이터 채널에게 주는 방식
- Cycle Steal 은 한번에 한 데이터 워드를 전송하고 버스의 제어를 CPU에게 돌려준다.
- Cycle Steal을 이용하면 입.출력 자료의 전송을 빠르게 처리해 주는 장점이있다.
<메모리 인터리빙>
- 인터리빙이란 여러 개의 독립 모듈로 이루어진 복수 모듈 메모리와 CPU간의 주소 버스가 한개로만 구성되어 있으면 같은 시각에 CPU로부터 여러 모듈들로 동시에 주소를 전달 할 수 없기 때문에 CPU가 각 각 모듈로 전송 할 주소를 교대로 배치한 후 차례대로 전송하여 여러모듈을 병행 접근하는 기법이다.
- CPU가 버스를 통해 주소를 전달하는 속도는 빠르지만 메모리 모듈의 처리 속도가 느리기 때문에 병행 접근이 가능하다.
- 메모리 인터리빙 기법을 사용하면 기억장치으 접근 시간을 효율적으로 높일 수 있으므로 캐시기억장치, 고속 DMA전송등에서 많이 사용한다.
<L1만 사용할 때의 액세스 시간>
* 찾는 자료가 L1캐시에 없을 경우 주기억장치에서 자료를 찾으므로 액세스 시간은 다음과 같다.
- 메모리 액세스 시간=L1히트시간+L1미스율*L1미스 패널티
- L1히트 시간: L1캐시에서 자료를 찾는데 걸리는 시간.
- L1미스율: L1캐시에 자료가 없을 확률로 주기억장치에서 자료를 찾아야함
- L1미스패널티: L1캐시에자료가없을 경우 주기억장치를 액세스 하는데 걸리는 시간,
*****전체 페이지 테이블의 크기='페이지수 X 페이지 테이블 엔트리의 크기'
****페이지 수는 가상 기억장소에서 사용 될 수 있는 페이지수를 의미하는것으로 '가상기억장소의 크기/페이지크기'이다.
<하드웨어적 인터럽트 판별 방식>
- 하드웨어 우선순위 인터럽트는 CPU와 Inerrupt르 요청할 수 있는 장치 사이에 장치 번호에 해당하는 버스를 병렬이나 직렬로 연결하ㄹ여 요청장치의 번호를 CPU에 알리는 방식이다.
- 하드웨어적인 방법은 장치 판별과정이 간단해서 응답 속도가 빠르다.
- 회로가 복잡하고 융통성이 없으며 추가적인 하드웨어가 필요하므로 비경제적이다.
- 하드웨어적인 방법은 직렬과 병렬 우선순위 부여방식이있다.
<직렬(Serial)우선순위 부여 방식>
- 직렬 우선순위 부여방식은 인터럽트가 발생하는 모든 장치를 1개의 회선에 직렬로 연결한다.
- 우선순위가 높은 장치를 선두에 위치시키고 나머지를 우선순위에 따라 차례로 연결한다.
- 직렬 우선순위 부여방식을 데이지 체인방식이라한다.
<컴퓨터의 제어장치>
프로그램카운터(순서기), 명령해독기(해독기), 번지해독기(주소처리기),명령레지스터, 부호기 등
<입출력인터페이스의 사용이유>
입.출력 인터페이스는 동작방식인 데이터 형식이 서로 다른 컴퓨터 내부의 주기억장치나 CPU의 레지스터와 외부.입출력 장치간의 2진정보를 원활하게 전송하기 위한것으로 마이크오퍼레이션 같은 명령의 차이때문은 아니다.
--->>속도의 차이, 접압레벨의 차이,전송사이클 길이의차이
<Micro Cycle Time 부여방식>
**Micro Cycle Time은 CPU클록주기와 Micro Cycle Time의 관계에 따라 동기고정식, 동기 가변식, 비동기식으로 구분된다.
<Micro Cycle Time 부여방식>
**Micro Cycle Time은 CPU클록주기와 Micro Cycle Time의 관계에 따라 동기고정식, 동기 가변식, 비동기식으로 구분된다.
- 동기고정식(Synchronous Fixed): 모든 마이크로 오퍼레이션의 동작시간이 같다고 가정하여 CPU Clock의 주기를 Micro Cycle Time과 같도록 정의하는 방식이다. 모든 마이크로 오퍼레이션 중에서 수행시간이 가장 긴 마이크로 오퍼레이션의 동작시간을 Micro Cycle Time으로 정한다. 모든 마이크로 오퍼레이션의 동작시간이 비슷할 떄 유리한 방식이다.
- 동기 가변식(Synchronous Variable): 수행시간이 유사한 Micro Operaition 끼리 그룹을 만들어, 각 그룹별로 서로 다른 Micro Cycle Time을 정의하는 방식이다. 마이크로 오퍼레이션 수행시간이 현저한 차이를 나타낼 때 사용한다. 동기 고정식에 비해 CPU시간 낭비를 줄일 수 있는 반면, 제어기의 구현은 조금 복잡하다. 각 그룹간 서로 다른 사이클 타임의 동기를 맞추기 위해 각 그룹간의 마이크로 사이클 타임을 정수배가 되게한다.
- 비동기식(Aysnchronous): 모든 마이크로 오퍼레이션에 대하여 서로 다른 Mycro Cycle Time을 정의하는 방식이다. CPU시간 낭비는 전혀없으나,제어기가 매우 복잡해지기 때문에 실제로는 거의 사용되지 않는다.
<인터럽트 사이클>
<채널>
특징: 채널은 CPU를 대신하여 주기억장치와 입.출력장치 사이에서 입출력을 제어하는 입.출력 전용 프로세서(IOP)이다.
채널 제어기는 채널 명령어로 작성된 채널 프로그램을 해독하고 실행하여 입출력 동작을 처리한다.
채널은 CPU로부터 입.출력 전송을 위한 명령어를 받으면 CPU와는 독립적으로 동작하여 입.출력을 완료한다.
채널은 주기억장치에 기억되어 있는 채널 프로그램의 수행과 자료의 전송을 위하여 주기억 장치에 접근한다.
채널은 CPU와 인터럽트로 통신한다.
종류:
<마이크로 오퍼레이션>
채널 제어기는 채널 명령어로 작성된 채널 프로그램을 해독하고 실행하여 입출력 동작을 처리한다.
채널은 CPU로부터 입.출력 전송을 위한 명령어를 받으면 CPU와는 독립적으로 동작하여 입.출력을 완료한다.
채널은 주기억장치에 기억되어 있는 채널 프로그램의 수행과 자료의 전송을 위하여 주기억 장치에 접근한다.
채널은 CPU와 인터럽트로 통신한다.
종류:
- 선택채널(Select Channel): 고속 입출력장치(자기 디스크,자기 테이프,자기드럼)와 입출력하기 위해 사용함, 특정한한개의 장치를 독점하여 입.출력함
- 다중채널(Multiplexer Channel): 저속 입출력장치(카드리더,프린터)를 제어하는 채널, 동시에 여러개의 입출력장치를 제어함
- BlockMultiplexerChannel: 고속입출력장치를 제어하는 채널, 동시에 여러개의 입.출력장치를 제어함
<마이크로 오퍼레이션>
- 마이크로 오퍼레이션은 Instruction을 수행하기 위해 CPU내의 레지스터와 플래그가 의미 있는 상태변환을 하도록 하는 동작이다.
- 마이크로 오퍼레이션은 레지스터에 저장된 데이터에 의해 이루어지는 동작이다.
- 마이크로 오퍼레이션은 한 개의 Clock Pulse 동안 실행되는 기본 동작이다.
- 마이크로 오퍼레이션은 컴퓨터의 모든 명령을 구성하고 있는 몇 가지 종류의 기본 동작이다.
- 마이크로 오퍼레이션의 순서를 결정하기 위하여 제어장치가 발생하는 신호를 제어신호라고 한다.
- 한 개의 Instruction은 여러 개의 Micro Operation이 동작되어 실행된다.

댓글
댓글 쓰기