(머신러닝) 2장 K-최근접 이웃 알고리즘
*영화를 장르별로 분류해 본적이 있는가?
로맨스영화에는 키스 장면이 더 많이 나오며, 액션 영화에는 발차기 장면이 더 많이 나온다. 영화마다 무언가를 판단 기준으로 삼는다면, 어떤 영화가 무슨 장르에 속하는 지 자동적으로 알아낼 수 있을 것이다.
1. 거리 측정을 이용하여 분류하기
<k-최근접 알고리즘(kNN)>
장점: 높은 정확도, 오류 데이터(outlier)둔감, 데이터에 대한 가정이 없음
단점: 계산 비용이 높음, 많은 메모리 요구
적용: 수치형 값, 명목형 값
기존에 훈련 집합이었던 예제 데이터 집합이 존재하며, 모든 데이터는 분류항목 표시가 붙어있다. 따라서 각각의 데이터가 어떤 분류 항목으로 구분되는 알 수 있다. 이후 분류항목표시가 붙어 있지 않은 새로운 데이터가 주어졌을 때, 기존의 모든 데이터와 새로운 데이터를 비교한다. 그리고 가장 유사한 데이터( 가장 근접한 이웃) 의 분류항목 표시를 살펴본다.
이때, 분류 항목을 이미 알고 있는 데이터 집합에서 상위 k개의 가장 유사한 데이터를 살펴보게 된다.(여기서 k는 일반적으로 20미만의 정수)마지막으로, k개의 가장 유사한 데이터들중 다수결을 통해 새로운 데이터의 분류 항목을 결정하게 된다.


거리를 내림차순으로 정렬하여 가장 가까운 k개의 영화를 찾아야 한다. k=3이라고 하자. 그러면 세 개의 가장 가까운 영화는 캘리포니아맨, 바보, 아름다운 여자
kNN알고리즘은 물음표에 해당하는 영화의 분류 항목을 결정하기 위하여 이 세개의 영화에서 다수결로 뽑힌것을 선정한다. 즉, 세 영화 모두 로맨스이므로 의문의 영화는 로맨스장르더,
2. kNN분류 알고리즘 실행하기
이 함수의 목적은 inX라고 불리는 하나의 데이터를 분류하기 위해 kNN알고리즘을 사용하는 것이다.
def classify0(inX, dataSet, labels, k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX, (dataSetSize-1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=lables[sortedDistIndices[i]]
classCount[voteIlable]=classCount.get(voteIlable,0)+1
sortedClassCount=sorted(classCount.iteritem(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
3. kNN을 이용하여 데이트 사이트의 만남 주선 개선하기
데이트를 했던 사람에게 세가지 유형이 있다.
<분석: 매스플롯라이브러리로 scatter 플롯 생성하기>
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
이런식으로 표현하면 두 데이터간의어떠한 관계도 파악하기 어렵다.
그래서 datingLabels 에 저장되어 있는 분류항목표시에 따라 크기와 색상을 다르게 보이도록 할 수 있다.
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels))
그러나 dataLabels 칼럼영역은 분류 항목 표시 값들이 문자형이기 때문에 오류가 난다, 그래서 분류 항목표시 값들을 정수형으로 변경해주어야 한다.
<준비: 수치형 값 정규화하기>
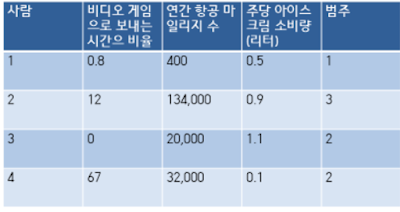
사람 3과 사람 4 간의 거리를 계산하자.

로맨스영화에는 키스 장면이 더 많이 나오며, 액션 영화에는 발차기 장면이 더 많이 나온다. 영화마다 무언가를 판단 기준으로 삼는다면, 어떤 영화가 무슨 장르에 속하는 지 자동적으로 알아낼 수 있을 것이다.
1. 거리 측정을 이용하여 분류하기
<k-최근접 알고리즘(kNN)>
장점: 높은 정확도, 오류 데이터(outlier)둔감, 데이터에 대한 가정이 없음
단점: 계산 비용이 높음, 많은 메모리 요구
적용: 수치형 값, 명목형 값
기존에 훈련 집합이었던 예제 데이터 집합이 존재하며, 모든 데이터는 분류항목 표시가 붙어있다. 따라서 각각의 데이터가 어떤 분류 항목으로 구분되는 알 수 있다. 이후 분류항목표시가 붙어 있지 않은 새로운 데이터가 주어졌을 때, 기존의 모든 데이터와 새로운 데이터를 비교한다. 그리고 가장 유사한 데이터( 가장 근접한 이웃) 의 분류항목 표시를 살펴본다.
이때, 분류 항목을 이미 알고 있는 데이터 집합에서 상위 k개의 가장 유사한 데이터를 살펴보게 된다.(여기서 k는 일반적으로 20미만의 정수)마지막으로, k개의 가장 유사한 데이터들중 다수결을 통해 새로운 데이터의 분류 항목을 결정하게 된다.
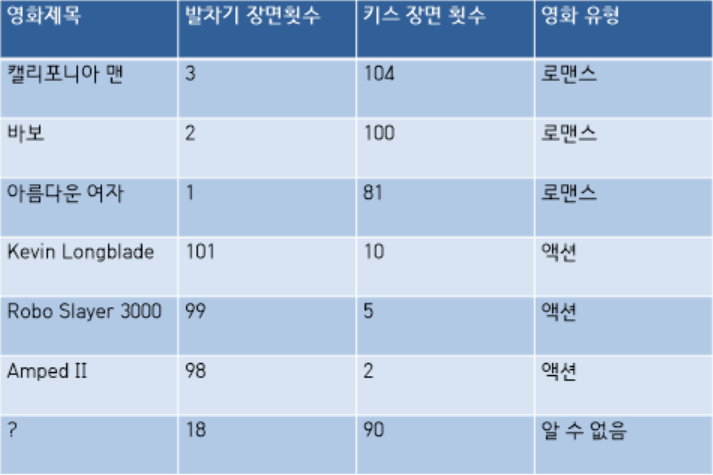
물음표에 해당하는 유형이 무엇인지는 알 수 없지만, 우선, 다른 모든 영화와의 거리를 계산 하는 것이다.

거리를 내림차순으로 정렬하여 가장 가까운 k개의 영화를 찾아야 한다. k=3이라고 하자. 그러면 세 개의 가장 가까운 영화는 캘리포니아맨, 바보, 아름다운 여자
kNN알고리즘은 물음표에 해당하는 영화의 분류 항목을 결정하기 위하여 이 세개의 영화에서 다수결로 뽑힌것을 선정한다. 즉, 세 영화 모두 로맨스이므로 의문의 영화는 로맨스장르더,
2. kNN분류 알고리즘 실행하기
이 함수의 목적은 inX라고 불리는 하나의 데이터를 분류하기 위해 kNN알고리즘을 사용하는 것이다.
def classify0(inX, dataSet, labels, k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX, (dataSetSize-1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=lables[sortedDistIndices[i]]
classCount[voteIlable]=classCount.get(voteIlable,0)+1
sortedClassCount=sorted(classCount.iteritem(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
3. kNN을 이용하여 데이트 사이트의 만남 주선 개선하기
데이트를 했던 사람에게 세가지 유형이 있다.
- 좋아하지 않았던 사람들
- 조금 좋아했던 사람들
- 많이 좋아했던 사람들
<텍스트 파일의 데이터 구문 분석하기>
4개의 칼럼* 1000개 행
이 함수는 하나의 파일명과 두 개의 출력을 처리한다.
def file2matrix(filename):
fr=open(filename)
numberOfLines=len(fr.readlines()) <---파일의 줄 수 구하기
returnMat=zeros((numberOfLines,3)) <----반환하기 위한 Numpy행렬 생성
classLabelVector=[]
fr=open(filename)
index=0
for line in fr.readlines():
line=line.strip() <----문자열 양끝에 있는 공백제거
line=line.strip() <----문자열 양끝에 있는 공백제거
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(listFromLine[-1])
index+=1
return returnMat, classLabelVector
<분석: 매스플롯라이브러리로 scatter 플롯 생성하기>
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
이런식으로 표현하면 두 데이터간의어떠한 관계도 파악하기 어렵다.
그래서 datingLabels 에 저장되어 있는 분류항목표시에 따라 크기와 색상을 다르게 보이도록 할 수 있다.
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels))
그러나 dataLabels 칼럼영역은 분류 항목 표시 값들이 문자형이기 때문에 오류가 난다, 그래서 분류 항목표시 값들을 정수형으로 변경해주어야 한다.
<준비: 수치형 값 정규화하기>
사람 3과 사람 4 간의 거리를 계산하자.
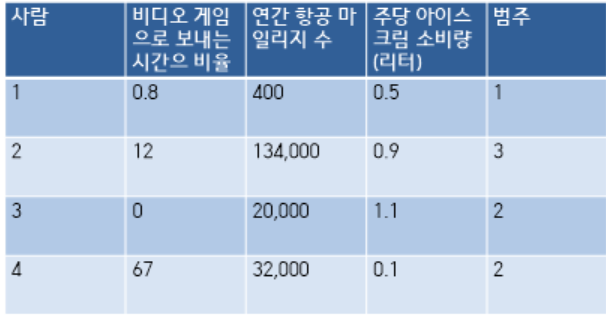
어떤 항목이 가장 큰 차이를 만드는가? 간격이 가장 큰 연간 항공 마일리지 수가 가장 큰 효과를 나타낼 것이다. 단지 값이 크다는 이유만으로 항공 마일리지 수가 중요하다고 할 수 있을까? 그렇지 않다. 이 항목은 다른 항목들과 똑같은 비중을 차지하고 있다.
서로 다른 범위에 놓여있는 값을 다룰 경우에는 이들을 정규화하는 것이 일반적이다. 일반적으로 정규화는 0에서 1또는 -1에서 1의 범위로 정한다.
0에서 1로 모든것의 범위를 정하기 위해서는
newValue=(oldValue-min)/(max-min)
max와 min은 데이터 집합에서 가장 큰 값과 작은 값이다.
이 정규화 하는 함수는 autoNorm()이다.

-->dataSet.min(0)에서 0은 로우가 아닌 칼럼으로 계산한다는 의미다.
정규화된 값을 얻기 위해 해당 칼럼내의 데이터에서 최솟값을 차감한 후 다시 range로 나눈다.( normDataSet=dataSet-tile(minVals,(m,1))
(normDataSet=normDataSet/tile(ranges, (m,1))
문제가 있다. minVals와 range는 1*3 행렬인데 데이터 행렬은 1000*3 행렬이다. 이 문제를 극복하기 위해 Numpy의 tile() 함수를 사용한다.
<검사: 전체 프로그램으로 분류기 검사하기>
기계학습에서 한 가지 공통된 작업은 알고리즘의 성능을 평가하는 것이다. 성능을 평가하는 한 가지 방법은 현재가지고 있는 데이터의 일부분, 즉 90% 정도를 가지고 분류기의 학습에 사용하는 것이다. 그런 다음 나머지 10%의 데이터를가지고 분류기를 검사하여, 분류기의 성능이 어느정도인지 알아본다.
---데이트하기 사이트를 위한 분류하기 검사코드------

댓글
댓글 쓰기