(Cassandra) 카산드라 데이터 모델
참고: http://meetup.toast.com/posts/58
*CQL테이블은 최소 1개 이상의 Column을 Primary key라는 것으로 지정해야하며, Cassandra는 이렇게 Primary key로 지정된 column들 중에서 partition key로 지정된 column의 value를 기준으로 데이터를 분산하게 된다.
* 카산드라의 칼럼은 실제로 컬럼이 업데이트된 마지막 시간을 기록하는 타임스탬프인 또 하나의 차원을 갖고 있다. 타임스탬프가 자동적인 메타데이터 속성은 아니지만, 클라이언트가 쓰기를 수행할 때 값과 함께 타임스탬프를 제공해야 한다. 타임스탬프는 쿼리할 수 없으며 순전히 서버측에서 충돌을 해결하는 용도로만 사용된다.
* 카산드라에서 키본 속성은 키스페이스별로 설정할 수 있다.
* CQL키 용어 정리
1)partition key
: partition key는 CQL문법에서 Cassandra에 data를 분산 저장하기 위한 unique한 key이다. partition key는 특정 table을 구성할 대 반드시 1개 이상이 지정되어야 하며, 여러개 지정될 수도 있다. partition key가 단 1개일 경우, 해당 partition key로 지정된 CQL Column의 Value가 실제 Cassandra Data Layer의 Row key 로 저장된다.
partition key가 여러 개 일 경우, 각 partition key로 지정된 CQL Column들의 value들을
":" 문자와 함께 조합한 값들이 실제 Cassandra Data Layer의 Row Key로 저장된다.
2) cluster key
: 아시다시피 Cassandra Data Layer에서 Row에 속한 모든 Column들은 항상 정렬된 상태로 저장된다.
따라서 cluster key는 이러한 정렬에 대한 기준 역할을 담당한다.
CQL에서 cluster key로 지정된 CQL Column들의 value들은 나머지 Column들의 name및 ":" 문자와 함꼐 조합되어,이 값이 실제 Cassandra Data Layer의 Column Name으로 저장된다. 만약 cluster key가 전혀 없는경우엔, CQL Column의 name이 그대로 Cassandra Data Layer의 Column Name이 된다.
3) primary key
: primary key는 CQL table에서의 각 row를 각자 unique하게 결정해주는 기준 역할을 담당한다.
primary key는 최소 1개이상의 partition key와 0개 이상의 cluster key로 구성된다.
4) composite key(=compound key)
: 1개이상의 CQL Column들로 이루어진 primary key를 composite key라 부른다.
5)composite partition key
: composite partition key는 2개 이상의 다수의 CQL Column으로 이루어진 partition key를 의미한다.
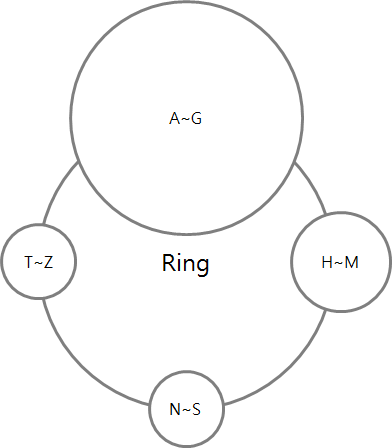
*Row Key를 token으로 변환해주는 모듈을 partitioner라고 부른다. conf/cassandra.yaml의 Partitioner항목을 보면 Cassandra가 어떤 partitioner을 사용했는지 확인 할 수 있으며 RandomPartitioner, Murmur3Partitioner, ByteOrderedPartitioner라는 이름의 세 가지 Partitioner를 제공한다.
RandomPartitioner는 Row Key를 MD5로 hashing하여 token을 생성한다. Murmur3Partitioner은 MurMur5로 해싱하여 token을 생선한다. 하지만 ByteOrderedPartitioner(이하 BOP)는 조금 다르다. BOP는 Row Key를 16진수 형태로 변환하여 이 값을 token으로 사용한다. 즉,BOP 변환된 token은 문자 순서로 정렬되어 각 노드에 분산된다는 이야기다. 만약 BOP를 쓴다면 Row Key들이 문자순서로 정렬되어 있으니 대용량 데이터를 특별한 가공 없이 그대로 range query를 할 수 있는 등, 여러가지로 편리하게 사용할 수 있다. 하지만 BOP는 Cassandra의 대표정 안티패턴 중 하나이다. 왜냐면 BOP를 사용할 경우 Hotspot이 발생 할 확률이 매우 높기 때문이다.
*CQL테이블은 최소 1개 이상의 Column을 Primary key라는 것으로 지정해야하며, Cassandra는 이렇게 Primary key로 지정된 column들 중에서 partition key로 지정된 column의 value를 기준으로 데이터를 분산하게 된다.
* 카산드라의 칼럼은 실제로 컬럼이 업데이트된 마지막 시간을 기록하는 타임스탬프인 또 하나의 차원을 갖고 있다. 타임스탬프가 자동적인 메타데이터 속성은 아니지만, 클라이언트가 쓰기를 수행할 때 값과 함께 타임스탬프를 제공해야 한다. 타임스탬프는 쿼리할 수 없으며 순전히 서버측에서 충돌을 해결하는 용도로만 사용된다.
* 카산드라에서 키본 속성은 키스페이스별로 설정할 수 있다.
- 복제계수: 간단히말하면 복제계수는 데이터의 각 로우에대해 복제본으로 동작할 노드의 개수를 말한다. 복제계수가 3이면 링에서 3개의 노드가 각 로우의 사본을 갖게 될 것이다. 이 복제는 클라이언트에서 투명하다. 복제계수는 더 높은일관성을 얻는 데 성능 비용을 얼마나 지불해야 할지를 결정하게 한다. 즉, 데이터 읽기와 쓰기에 대한 일관성 레벨은 복제 계수를 따른다.
- 복제본 배치전략(Replica placement strategy): 복제본 배치는 복제본이 링에 배치되는 방법을 말한다. 카산드라에서는 어떤 노드가 어떤 키의 복사본을 갖게 될지 결정하는 다양한 전략이 있다. 이들 전략에는 SimpleStrategy, OldNetworkTopology, NetworkTopologyStrategy가 있다.
- 컬럼 패밀리: 마찬가지로 데이터베이스는 테이블의 컨테이너이고, 키스페이스는 하나 이상의 컬럼 패밀리 목록에 대한 컨테이너다. 컬럼패밀리는 관계형 모델의 테이블과 대체로 비슷하고, 로우의 컬렉션에 대한 컨테이너다. 각 로우는 정렬된 컬럼을 포함한다. 컬럼 패밀리는 데이터의 구조를 표현한다. 각 키스페이스는 최소한 하나 이상의 컬럼 패밀리를 갖고 있으며, 보통은 다수의 칼럼 패밀리를 갖는다.
<컬럼 패밀리 옵션>
- key_cached: 하나의 SSTable마다 캐시를 유지할 키의 개수,key_cached는 컬럼 이름/값은 전혀 참조하지 않으며 키의 갯수만 참조한다.이는 컬럼패밀리당 로우의 개수이며,메모리상에서 LRU 순으로 유지하기 위한것이다.
- row_cached: 메모리에 캐시할 전체 콘텐트(고유 로우키에대한 이름/값 쌍의 전체목록) 의 로우 개수
- read_repair_chance: 0과 1사이의 값을 지정한다. 이 값은 쿼럼(quorum)을 지정하지 않고 쿼리를
* CQL키 용어 정리
1)partition key
: partition key는 CQL문법에서 Cassandra에 data를 분산 저장하기 위한 unique한 key이다. partition key는 특정 table을 구성할 대 반드시 1개 이상이 지정되어야 하며, 여러개 지정될 수도 있다. partition key가 단 1개일 경우, 해당 partition key로 지정된 CQL Column의 Value가 실제 Cassandra Data Layer의 Row key 로 저장된다.
partition key가 여러 개 일 경우, 각 partition key로 지정된 CQL Column들의 value들을
":" 문자와 함께 조합한 값들이 실제 Cassandra Data Layer의 Row Key로 저장된다.
2) cluster key
: 아시다시피 Cassandra Data Layer에서 Row에 속한 모든 Column들은 항상 정렬된 상태로 저장된다.
따라서 cluster key는 이러한 정렬에 대한 기준 역할을 담당한다.
CQL에서 cluster key로 지정된 CQL Column들의 value들은 나머지 Column들의 name및 ":" 문자와 함꼐 조합되어,이 값이 실제 Cassandra Data Layer의 Column Name으로 저장된다. 만약 cluster key가 전혀 없는경우엔, CQL Column의 name이 그대로 Cassandra Data Layer의 Column Name이 된다.
3) primary key
: primary key는 CQL table에서의 각 row를 각자 unique하게 결정해주는 기준 역할을 담당한다.
primary key는 최소 1개이상의 partition key와 0개 이상의 cluster key로 구성된다.
4) composite key(=compound key)
: 1개이상의 CQL Column들로 이루어진 primary key를 composite key라 부른다.
5)composite partition key
: composite partition key는 2개 이상의 다수의 CQL Column으로 이루어진 partition key를 의미한다.
*Row Key를 token으로 변환해주는 모듈을 partitioner라고 부른다. conf/cassandra.yaml의 Partitioner항목을 보면 Cassandra가 어떤 partitioner을 사용했는지 확인 할 수 있으며 RandomPartitioner, Murmur3Partitioner, ByteOrderedPartitioner라는 이름의 세 가지 Partitioner를 제공한다.
RandomPartitioner는 Row Key를 MD5로 hashing하여 token을 생성한다. Murmur3Partitioner은 MurMur5로 해싱하여 token을 생선한다. 하지만 ByteOrderedPartitioner(이하 BOP)는 조금 다르다. BOP는 Row Key를 16진수 형태로 변환하여 이 값을 token으로 사용한다. 즉,BOP 변환된 token은 문자 순서로 정렬되어 각 노드에 분산된다는 이야기다. 만약 BOP를 쓴다면 Row Key들이 문자순서로 정렬되어 있으니 대용량 데이터를 특별한 가공 없이 그대로 range query를 할 수 있는 등, 여러가지로 편리하게 사용할 수 있다. 하지만 BOP는 Cassandra의 대표정 안티패턴 중 하나이다. 왜냐면 BOP를 사용할 경우 Hotspot이 발생 할 확률이 매우 높기 때문이다.
BOP를 사용하여 Row Key문자 순서대로 각 노드 별로 데이터를 분산하게 된다면, 모든 노드에 데이터를 균일하게 분산하기 위해서는 데이터의 분산기준을 담당하는 Row key자체가 모든 문자열에 대애허 균일하게 분포해야 한다. 하지만 현실은 그렇지 않다. 특정 문자로 밀집되어 있는 Row key들을 저장하는 노드가 자연스럽게 Hotspot이 되어버린다.
더구나 이는 단순히 노드를 늘리거나 줄인다고 해결될 일이 아니다. 노드를 늘렸더니 오히려 전혀 사용하지 않는 노드가 다수 생길 수도 있고, 노드를 줄였더니 더 심각한 Hotspot이 생겨버릴 수도 있기 때문이다. 이는 BOP의 경우 분산의 정도가 전적으로 Row key의 분포에 달려있기 때문이다.
이러한 이유로 디폴트는 Murmur3Partitioner을 사용한다. 이것을 사용함으로 모든 데이터를 비교적 균일하게 모든 노드에 분산 할 수 있는 것이다. Murmur3 hash function을 사용할 때 단점도 존재한다. 문자열이 아닌 Hash값을 기준으로 정렬하여 각 노드에 저장되므로 , Row key의 문자열로 정렬된 데이터가 필요 할 경우엔 사용자는 모든 데이터를 가져온 다음에 Application Layer에서 직접 데이터를 가공하여 정렬하여야 한다. 가령 엄청난 양의 데이터가 분산되어 저장되어 있는데, Row key를 기준으로 데이터를 paging하는 등의 작업은 불가능한 일이다. 그 많은 데이터를 모두 가져와서 직접 정렬해야 최종적으로 사용자가 원하는 위치의 데이터 집합을 뽑아 낼 수 있다.
지금까지 Partitioner에 대해 대략적으로 짚어 보았으니 이번엔 Cassandra의 Data Consistency와 Replication에 대해 간단히 알아볼 차례입니다.
Cassandra는 기본적으로 CQL을 통해 쿼리 시점에 Read와 Wirte에 따른 다양한 Consistency Level을 통해서 몇 개의 Replication을 통해 어느 정도 수준의 데이터 일관성을 확보 할 것인지 선택 할 수 있습니다. 또한, 처음 Keyspace 생성 할 때 Replication의 배치 전략과 그 전략에 맞는 Replication 복제 개수, 위치 위치를 결정 할 수 있죠. 그리고 이러한 기능을 지원하기 위해서 conf/cassandra.yaml의 endpoin_snitch 항목에 snitch의 종류를 세팅하게 됩니다. 그러면 snitch란 뭘까요? 쉽게 말하자면, 데이터센터가 어떻게 구성되어있는지, 장비가 설치된 렉이 어떻게 나뉘어져 있는지에 대한 topology를 Cassandra에게 알려주기 위한 옵션입니다.
Cassandra에서 제공하는 snitch의 종류는 매우 다양합니다. snitch는 단순히 1개의 Data Center를 가정한 것도 있고, 다수의 Data Center에 다양한 Rack 배치까지 고려한 것도 있으며, 심지어 Cloud Stack이나 Google Cloud와 같은 Cloud 서비스에 특화된 snitch도 존재합니다. 이러한 snitch를 바탕으로 Cassandra는 사용자가 정의한 스키마에 따라서 어느 Data Center의 어느 Rack에다가 각각 몇 개의 Replication Data를 나누어 저장 할 것인지 등을 결정하는 것이죠. 그리고 이렇게 구성된 Cassandra에 사용자가 데이터를 CRUD하고자 한다면, 사용자가 해당 쿼리와 함께 지정한 Consistency Level을 통하여 데이터를 처리하게 됩니다.
Read/Write에 따른 Consistency Level의 종류와 특징, 다양한 snitch들 각각의 자세한 설명들은 분량상 이 글에서 모두 다루기 힘들기 때문에 Datastax의 공식문서를 참조하시길 부탁드립니다. ( 참조 링크 : Snitch, Data Consistency )
Cassandra는 기본적으로 CQL을 통해 쿼리 시점에 Read와 Wirte에 따른 다양한 Consistency Level을 통해서 몇 개의 Replication을 통해 어느 정도 수준의 데이터 일관성을 확보 할 것인지 선택 할 수 있습니다. 또한, 처음 Keyspace 생성 할 때 Replication의 배치 전략과 그 전략에 맞는 Replication 복제 개수, 위치 위치를 결정 할 수 있죠. 그리고 이러한 기능을 지원하기 위해서 conf/cassandra.yaml의 endpoin_snitch 항목에 snitch의 종류를 세팅하게 됩니다. 그러면 snitch란 뭘까요? 쉽게 말하자면, 데이터센터가 어떻게 구성되어있는지, 장비가 설치된 렉이 어떻게 나뉘어져 있는지에 대한 topology를 Cassandra에게 알려주기 위한 옵션입니다.
Cassandra에서 제공하는 snitch의 종류는 매우 다양합니다. snitch는 단순히 1개의 Data Center를 가정한 것도 있고, 다수의 Data Center에 다양한 Rack 배치까지 고려한 것도 있으며, 심지어 Cloud Stack이나 Google Cloud와 같은 Cloud 서비스에 특화된 snitch도 존재합니다. 이러한 snitch를 바탕으로 Cassandra는 사용자가 정의한 스키마에 따라서 어느 Data Center의 어느 Rack에다가 각각 몇 개의 Replication Data를 나누어 저장 할 것인지 등을 결정하는 것이죠. 그리고 이렇게 구성된 Cassandra에 사용자가 데이터를 CRUD하고자 한다면, 사용자가 해당 쿼리와 함께 지정한 Consistency Level을 통하여 데이터를 처리하게 됩니다.
Read/Write에 따른 Consistency Level의 종류와 특징, 다양한 snitch들 각각의 자세한 설명들은 분량상 이 글에서 모두 다루기 힘들기 때문에 Datastax의 공식문서를 참조하시길 부탁드립니다. ( 참조 링크 : Snitch, Data Consistency )
*결론부터 말하자면 하나의 Partition Key(Row Key)이 무한히 데이터를 저장하지 말라는 것이죠

댓글
댓글 쓰기